Ways to Optimize Data Ingestion and Analysis with AWS Glue
Aug 27, 2018

The wealth of data and information that resides in databases from one organization to the next is only as valuable or useful as the tools that are able to extract that information and the subsequent analysis that uncovers usable knowledge. As companies move their applications and data into cloud implementations, the ability to aggregate many disparate data sources into a single data store and be able to easily query the data becomes critical for their continued operations.
There are many challenges that come with attempting to consolidate different data sources and schemas into a single location. Either time needs to be spent during the migration of the data to normalize the data into a common schema, or the tools that ultimately query that combined data need to be robust enough to be able to handle the complexities of different data sets without impacting report generation latency.
The Challenge – Data Analysis
A recent client of ClearScale experienced this concerning scenario. The organization had amassed an enormous amount of customer transactional data from a number of different sources in a diversity of data formats. From store-level transactions to coupon redemption, app clicks, email clicks, and social media, the client had many different views of its customers’ buying behavior.
With all of this wealth of information, the client struggled with finding a way to distill it down into a singular view of a customer’s shopping and buying habits. With the goal being to increase sales by leveraging customer purchasing behavior through direct marketing offers, the client needed to find a way to not only consolidate the data, but find ways to analyze it effectively.
The ClearScale Solution – Data Lake
In a traditional data warehouse model, ClearScale would have typically taken the client’s data and stored it in the warehouse after cleaning it up and normalizing it utilizing Extract-Transform-Load (ETL) processes. Unfortunately, this approach using existing ETL ingestion technologies can be challenging to set up and maintain as the ETL processes have to be constantly tweaked to account for ever-changing datasets or schemas as new data sources become available.
One way around this problem is to not spend the time to set up normalized ETL ingestion processes, but instead allow the data to live in its natural state, albeit in a centralized location. In this approach, it then falls upon the shoulders of the analysis tools to normalize the data before returning the expected results. This is not ideal because the process of normalizing the data can not only increase the latency of generating reports but potentially cause errors in the resulting data results due to issues from the transformation/normalization process.
To avoid this, ClearScale decided a data lake model would be a more viable approach. In this model, there are three components that make this approach ideal. First, a data store is able to hold arbitrarily formatted data. Second, a data processing/transformation engine to move the data around and reformat it. Finally, a query engine that works well with semi-structured data during the data analysis phase of generating reports. ClearScale determined that in order to successfully implement a solution like this that they would need to rely on the AWS Glue family of services, (like AWS Glue Crawler) a service designed to create the base data schema and ETL functionality that would allow for the data to be transformed for easier processing later.
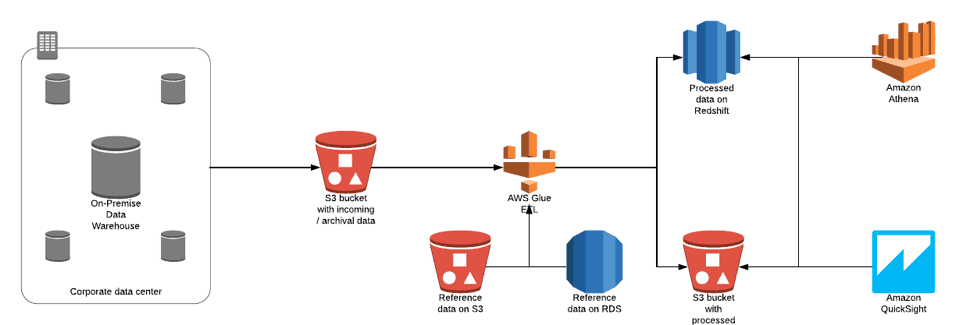
Figure 1- A Typical AWS Glue ETL Model
ClearScale executed against this plan by setting up S3 buckets for the data that needed to be stored and then integrated with the client’s data warehouse and data feeds to ingest the data into the S3 instances. By then ingesting a sample set of data into the S3 buckets, ClearScale was able to leverage the power of AWS Glue Crawler to create the initial database schema. ClearScale then used AWS Athena to perform a test run against the schemas and fixed issues with the schema manually until Athena was able to perform a complete test run without errors from the data catalog.
Once this effort was completed, ClearScale then worked with the AWS Glue Development Endpoints to create ETL Jobs for each data source. To do this, a dataset was read from a data source specified by AWS Glue Data Catalog and then the dataset’s schema was mapped from input to output. If necessary, additional transformations were created until the ideal mapping was achieved and the dataset output was saved into the S3 buckets. Finally, this development endpoint script was converted into AWS Glue ETL jobs and tested against the sample data.
Even with this extensive and robust approach to aggregation and transformation of data, there were bound to be issues requiring optimization of the entire pipeline. As an example, ClearScale encountered a situation where one of the jobs began performing poorly: a 1 GigaByte dataset was processing for more than 12 hours on 10 Data Processing Units (DPUs).
To identify the root cause, ClearScale ran the job on an AWS Glue Development Endpoint which has built-in Spark debugging tools such as Spark UI or Spark History Server. They also went through the logs in AWS CloudWatch and reviewed the extended metrics to identify areas that might be causing bottlenecks in the ETL processing. Through the identification of these bottlenecks, ClearScale was then able to address areas of concern in the ETL Jobs. The end result was an order of magnitude improvement in the job time with more improvements coming.
The Benefits
By taking this approach, ClearScale was able to consolidate all the data the client had acquired over time and transformed it in a way that allowed them to query, analyze, and then individually target markets to each unique customer based on the customer’s buying behaviors, resulting in increased revenue generation.
From a technology perspective, implementing AWS Glue Crawler and other AWS services within the client’s AWS account provided a stable foundation for future data projects and queries. Finally, it gave the client the opportunity to leverage other AWS services, such as Redshift or Athena, and then overlay those with business intelligence and analytic toolsets, like Tableau, for data mining and reporting.
ClearScale’s technical acumen, accumulated over many years and numerous client projects, has allowed us to be recognized by Amazon as a Premier Consulting Partner with multiple competencies. Our approach to solving our clients’ needs stems from our ability to recognize and understand underlying operational concerns and solve those particular issues.