Is Your Data Ready for Generative AI?
Aug 8, 2023

By Jeff Carson, VP of Strategy and Solutions, ClearScale
Generative AI (GenAI) is all the rage in the world today, thanks to the advent of tools like ChatGPT and DALL-E. To their credit, these innovations are extraordinary. They’ve put the power of Artificial Intelligence and Machine Learning (AI/ML) into the hands of everyday users. However, these tools have also skewed our perceptions of what is most important right now in the age of accessible AI/ML.
GenAI is one subset of data science. There are other aspects of data science that businesses of all sizes can take advantage of. The hurdle that most companies will have to jump concerning data science is a fact-based hurdle, not a technical one. The fact is this: you cannot have a data science strategy if you do not have a data strategy. Too many leaders are putting the cart before the horse right now – they are investing in GenAI before having a clear understanding of how to unify, store, analyze, and apply data at scale. These fundamental capabilities are being overlooked, which will lead to challenges down the road when trying to create value with data science initiatives, including GenAI.
At ClearScale, we believe the answer to long-term success with AI/ML is to pursue data readiness. Data readiness for GenAI means putting the right processes and architecture in place to manage big data effectively. The great news for organizations is that pursuing data readiness for AI is valuable in and of itself. There is still significant opportunity to innovate, improve services, and drive growth with big data before introducing GenAI to the mix. What’s more, cloud service providers, like AWS, make this easier than ever today. Let’s see why.
How Do I Achieve Data Readiness for GenAI?
Data readiness exists when the following two components live in harmony under a comprehensive data strategy:
- Data Architecture
- Data Engineering
- Data Science
Data Architecture
Data architecture refers to the tools and resources we use to get data into a state where it can be engineered for data science pursuits. Think of it this way, if data is the new oil, the well has to be dug and the derrick installed to get it out of the ground, consistently, efficiently, and dependably.
AWS offers a variety of tools for deploying data architectural patterns. These include data lakes, data ingestion pipelines, data warehouses, data marts, and data migration tools. The process involves designing and building a specific data architecture. This architecture unifies organizational data in a certain pattern. It provides a 360-degree view of the data needed to answer business questions. These are the questions that data science seeks to answer. If engineers don’t architect the data well for engineering activities, it can hamper progress. This applies to both unified, holistic organizational data and divided, distributed data. Both can equally obstruct progress in data science, including GenAI. Getting the data architecture right is the first step. It helps in drawing insights from the massive volumes of data available to organizations today.
Data Engineering
Data engineering is how we get data ready for the complex work that data scientists and machine learning engineers do. Think of it this way, if data is the new oil, the crude will have to be refined into usable ‘products.’ Data engineering involves activities like data processing (e.g., cleaning, categorizing, labeling, etc.), data analytics, and data visualization.
It also includes ETL jobs that move data into purpose-built data stores, such as data marts and data warehouses for downstream analysis, inclusive of data scientists. Data can be engineered for purpose in transit between data architecture components. Or it can be engineered in place depending on the nature of the component.
Data Science
Data science is the practice of using software development and statistics within a specific domain. This assumes that the data is properly prepared. Consider this analogy: if data is the new oil, it must be refined into usable ‘products.’ Someone must then apply these products in the real world to maximize their value.
This is the role of data scientists and machine learning engineers. They structure data for consistent delivery and availability. Then, they prepare and analyze it to ensure it’s complete in engineering. They can use AWS AI/ML managed services, Amazon SageMaker’s low code or no code tools, or custom models in SageMaker. These tools help derive insights from the data. These insights can answer business questions. If answered well, they can transform the business.
The Importance of Data Readiness and Strategic Implementation
The challenge is that many enterprises overlook the importance of building a basic, yet effective data strategy as the roadmap for a healthy and sustained data science practice that can serve as the foundation for larger GenAI efforts. They hire data scientists and expect them to operate across all three of the areas above. This leads to mixed results or good results at poor velocities. This should only really happen in startups or small businesses with limited resources.
The ideal approach to leveraging GenAI is to invest thoroughly in data architecture, data engineering, and data science, which require a multitude of technologies and skills. And then these lanes have to come together under a well-defined data strategy. Companies that implement Generative AI without these components in place are building on top of a house of cards that can’t deliver real value.
Fortunately, AWS makes it easy to achieve data readiness by offering solutions across the entire data management spectrum. These solutions are available as pay-as-you-go managed services, so companies don’t have to deal with the underlying IT infrastructure. Put simply, AWS gives modern enterprises everything needed to unlock data readiness for GenAI. Of course, this is easier said than done, which is where ClearScale comes in.
How Do ClearScale and AWS Enable Data Readiness for AI?
ClearScale is an AWS Premier Tier Services Partner with a long history of data management excellence on the cloud. We help organizations transform their data architecture and capabilities to create value, unleash innovation, and deliver better services at scale. Our solutions architects and engineers have earned 100+ AWS technical certifications. And ClearScale has earned 11 AWS competencies, including the Data and Analytics and Machine Learning competencies. These achievements demonstrate our ability to deliver technical data solutions that set the foundation for Generative AI.
In fact, we have expertise in the bottom four layers of The Data Science Hierarchy of Needs, created by data scientist Monica Rogati. Our data architecture and data engineering services cover the following four layers of the pyramid:
- Collect
- Move/Store
- Explore/Transform
- Aggregate/Label
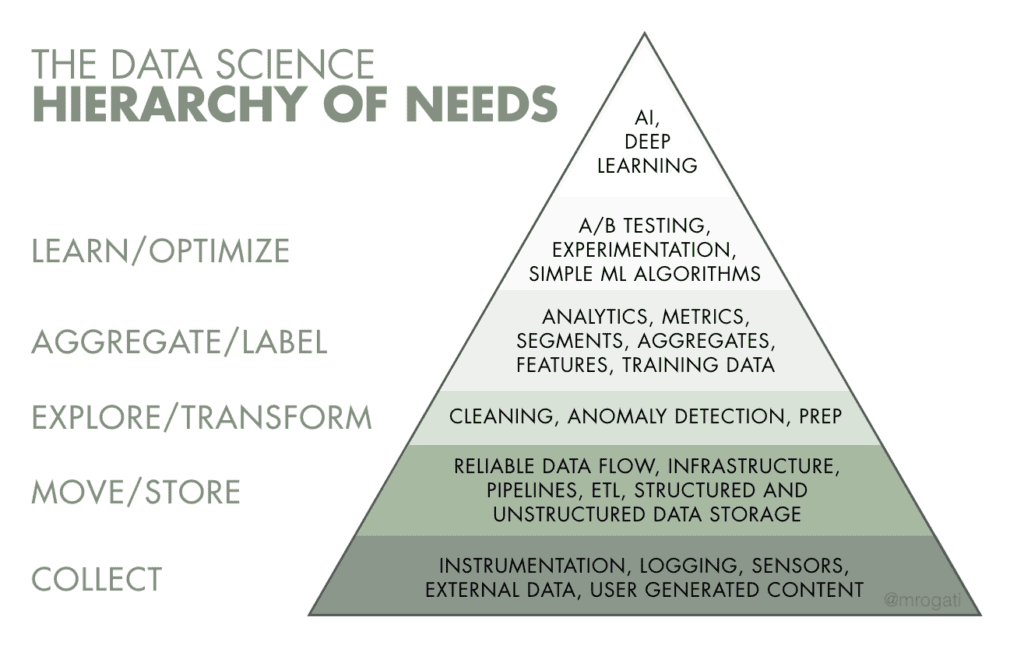
We know exactly what AWS solutions and components to use at each level to address our clients’ needs. The teams we work with can then build on top of the foundation we establish on the AWS cloud to learn from their data, optimize data operations, and explore more advanced AI / deep learning use cases.
Data Readiness Case Studies
For instance, we helped a client in the healthcare space rethink its data architecture to make it easier to work with vast amounts of sensitive patient data. We created a data lake on top of Amazon S3. And we introduced our client to solutions like AWS Config and AWS Control Tower. These services make it easier to manage multi-account cloud environments and protect sensitive data according to strict compliance requirements. Now, our client’s data architecture is more reliable, secure, and scalable, setting the foundation for more advanced data science work.
We also helped a company that offers enterprise form automation solutions revamp its data management infrastructure. Our client wanted to give users more information about their product utilization, as well as enhance the organization’s overall data science capabilities. We worked with the internal team to set up a secure data lake, a scalable data ingestion layer, and a flexible warehousing and reporting layer. Together, these components enabled a superior end-user experience and paved the way for sophisticated big data workloads.
In another engagement, we worked with a digital services firm to upgrade the company’s data ecosystem to handle big data velocities and volumes. We set up a data lake house for the client and used AWS ML tools to extract value from the aggregated data in the cloud. As a result, our client is now able to ingest, process, and analyze data with tremendous efficiency. This led to better decision-making and scalability.
Harnessing the Power of Generative AI with GenAI AppLink™
The tech world has been humming with conversations surrounding generative AI over the past year. Amidst the excitement and, at times, confusion, ClearScale, has taken a monumental leap by launching GenAI AppLink™. This innovative solution promises seamless integration of the Generative AI (GenAI) workflow into an AWS environment, bridging the gap between an organization’s application and the vast expanse of Language Learning Models (LLMs).
GenAI AppLink is built around Amazon Bedrock. As worded by AWS, Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API, along with a broad set of capabilities you need to build generative AI applications, simplifying development while maintaining privacy and security.
The purpose of GenAI AppLink is to act as an out-of-the-box solution that ClearScale can implement in your AWS environment and its job is to showcase what’s possible with your application workflow and a foundational model provided by Amazon Bedrock.

About GenAI AppLink™
Here’s a glimpse of what GenAI AppLink™ offers:
- A robust and ready-to-use solution effortlessly integrated into any AWS environment.
- A mixture of impressive features such as document summarization, retrieval augmented generation search (RAG), natural language SQL Query processing, image generation, and more.
- Custom prompts to ensure the responses from the Amazon Bedrock API are not merely data points but actionable business insights.
- Comprehensive documentation by ClearScale, ensuring a smooth implementation journey tailored to your application’s specific needs.
Generative AI applications like ChatGPT and DALL-E have not only caught the public’s attention but have showcased the capability to turn raw data into actionable intelligence. McKinsey and Company’s research sheds light on the immense potential, estimating an annual economic benefit ranging from $2.6 trillion to $4.4 trillion by applying GenAI across diverse sectors.
Yet, the path to leveraging generative AI is strewn with challenges. Companies often grapple with preparing data for LLM usage and the intricacies of integrating these models into existing workflows. GenAI AppLink™ is ClearScale’s answer to these hurdles, offering a solution that not only simplifies the process but amplifies the benefits.
Data Readiness Next Steps
If you’re hoping to leverage Generative AI in your organization, make sure you’re ready. Build a robust data science practice first that’s based on sound data architecture and data engineering principles. Ensure your data is accessible and reliable for those who need it. And implement efficient data processing and analysis to uncover new insights for your AI projects.
Innovation in this space is happening at a dizzying pace. Rather than jump on the latest bandwagon, let us help you build a sustainable data foundation that is ready for yesterday, today, and whatever tomorrow brings.
If you need expert advice or help to execute your goals on AWS, ClearScale is here.
Get in touch today to speak with a cloud expert and discuss how we can help:
Call us at 1-800-591-0442
Send us an email at sales@clearscale.com
Fill out a Contact Form
Read our Customer Case Studies
