How to Implement Logging and Tracing for Containers
Apr 26, 2022

By Alexandr Ivenin, Systems Technical Lead, ClearScale
Logging and tracing are critical for maintaining IT infrastructure. Without logging and tracing, troubleshooting technical issues is hard, and evaluating operational performance is near impossible. Consequently, engineering teams can’t optimize applications for end-users, at least not quickly or efficiently.
Logging and tracing are particularly important for organizations that practice DevOps and depend on containerized applications in the cloud. Rapid iteration is crucial, but it introduces more risk to the development process. That’s why system administrators and developers need to know as soon as something goes wrong.
Fortunately, there are cloud-based solutions and technology stacks that simplify logging and tracing significantly. Amazon Web Services (AWS) tools are especially useful when combined with certain open-source software. In this blog post, we’ll cover several approaches IT leaders can take on the AWS cloud to implement logging and tracing across even the most complex infrastructure.
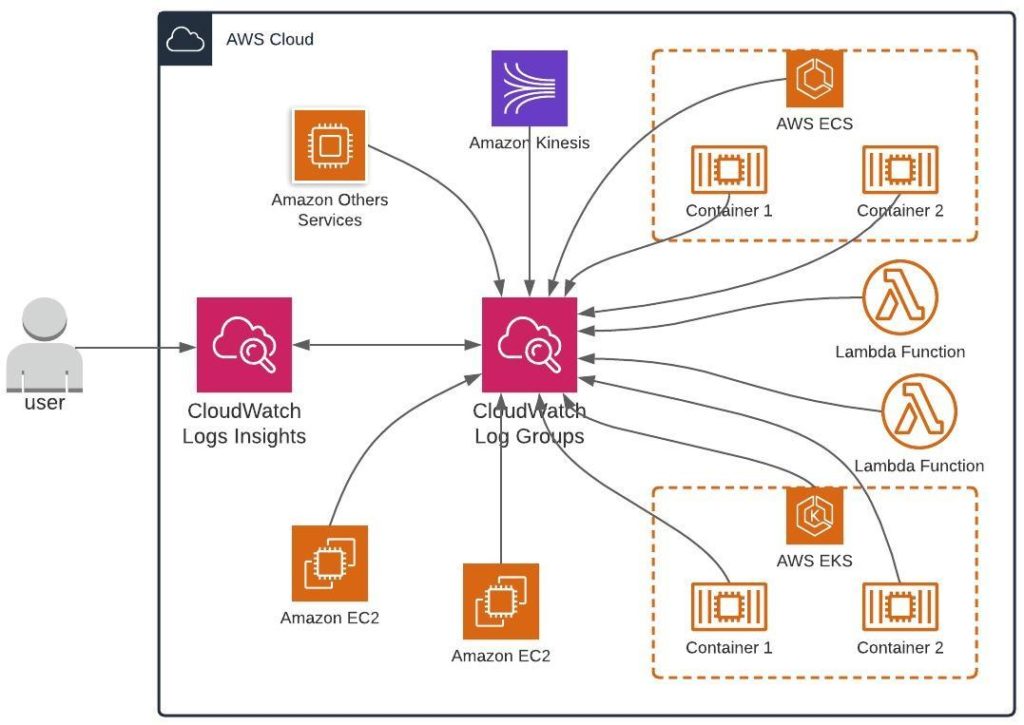
Amazon CloudWatch
One popular strategy for logging involves using Amazon CloudWatch, a monitoring and observability service that gives engineering teams complete visibility into IT infrastructure. CloudWatch can consolidate logging data from numerous sources – systems, applications, AWS services (e.g., Amazon EC2, CloudTrail, Route 53, etc.). The solution makes it easy for users to view logs, search for errors, and archive critical information. Additionally, system administrators and developers can use CloudWatch Logs Insights to run queries and create visualizations. Overall, Amazon CloudWatch is a viable option for logging. However, we believe there’s a better path for containers that involves several different tools.
Elasticsearch-based Logging
At ClearScale, we prefer Elasticsearch-based logging that leverages AWS managed services. Elasticsearch is a powerful search engine based on Apache Lucene that allows engineering teams to perform log analytics, monitor operational performance, conduct full-text searches, and more. Elasticsearch is one of the most widely used tools today due to its distributed, cost-efficient, and scalable nature.
AWS provides managed services through Amazon OpenSearch Service. The tool streamlines logging, monitoring, and querying so that users can deploy Elasticsearch’s capabilities effectively. However, we suggest using Elasticsearch specifically for log storage and then adding a suite of other complementary tools:
- Logstash or Fluentd for server-side data ingestion
- Kibana for visualizing logging data
- Kafka for caching log data in huge production environments
Elasticsearch, Fluentd or Logstash, and Kibana (EFK)
Logstash and Fluentd are two different open-source, server-side log collecting tools. Logstash is a free data processing pipeline that can gather and transform log data from diverse sources and then send that information to other locations, like Elasticsearch. Fluentd is also free, scalable, and a proven tool across the industry. It treats logs as JSON assets and gives users lots of flexibility when it comes to managing data.
Kibana is another open-source tool that allows engineers to create compelling dashboards and visualizations for Elasticsearch data and web application-related HTTP logs. Users can see how many HTTP requests were made within different time frames and use that information to determine why certain errors or issues occurred across containerized infrastructure. IT teams can also combine visualizations into a single dashboard, making it easy to search for logs in known problem periods, detect anomalies, configure alerts, or create custom search patterns.
Our engineers prefer using Elasticsearch, Fluentd, and Kibana (EFK) for small and medium-sized environments involving containerized applications. This stack is easily deployable through a Terraform template – users can have log processing up within 30 minutes.

For bigger production environments, we recommend using Logstash and adding a caching tier before data goes to Elasticsearch for processing. Apache Kafka works well here for buffering incoming log streams from containers. AWS has a fully managed service, AWS MSK, that enables users to get up and running immediately with Kafka. The combination of Kafka, MSK, and Logstash is ideal for processing large volumes of incoming logs.

Adding Tracing to the Mix
To really optimize IT infrastructure maintenance, organizations need to incorporate tracing on top of their logging stack. Logging is essential for consolidating events and performing analysis based on a snapshot of operational activity. Tracing, on the other hand, involves keeping a continuous view of application performance to discover bottlenecks or processes that could potentially detract from the overall user experience.
Tracing can be much more intense and complex from an implementation perspective, which is why it’s not always necessary for smaller organizations with less-complex infrastructure. Bigger enterprises with containerized apps and large user bases often benefit from tracing.
For those who want to implement tracing on AWS, we recommend using AWS X-Ray, a tool for debugging distributed applications. AWS X-Ray collects request data and provides an end-to-end view of application performance. Engineering teams can see detailed information about requests, responses, and even calls applications make to downstream infrastructure – other AWS resources, databases, APIs, and microservices.
Together, AWS X-Ray and the right logging stack empower IT teams to maximize cloud IT infrastructure, particularly when it comes to containerized applications. Organizations can keep applications running at peak performance, mitigate future problems, and keep end users – all essential in modern software development.

For those who need extra support taking advantage of AWS logging tools or establishing a monitoring stack, schedule a call with ClearScale today. Our cloud containers services will help you design and implement the ideal solution for your containerized infrastructure.
Call us at 1-800-591-0442
Send us an email at sales@clearscale.com
Fill out a Contact Form
Read our Customer Case Studies