How ClearScale Streamlined Machine Learning Data Prep at American College of Radiology with Amazon SageMaker Low-Code / No-Code
Oct 24, 2023

By Anthony Loss, Director of Solution Strategy at ClearScale and Mateusz Cebularz, Data Engineering Practice Lead at ClearScale
If you’ve ever spoken to a data scientist or a machine learning engineer, you’ll find that when it comes to data preparation, they have the same tune. They might report spending only about one-third of their time on actual machine learning (ML) problems, with the rest of the time spent on data preparation. This essential step involves locating data, visualizing it, cleaning it, and enriching it with feature engineering.
In the beginning stages of an ML project, a lot of manual effort goes into this, relying heavily on intuition and experience. The iterative process of modifying data transformations and analyzing results is monotonous and usually, mistakes are made. Even after finding an optimal transformation for a model, replicating and automating the data preparation process in a production setting can introduce more errors due to the manual nature of the initial experiments.
As you can see, building ML models isn’t as straightforward as one might imagine due to several inherent challenges. Firstly, it isn’t easy to sidestep the time-consuming nature of the data preparation phase. Given that the quality of an ML model is heavily dependent on the quality of the data fed into it, lots of time must be dedicated to cleaning and transforming the data. Also, ML modeling isn’t just about having the right tools but also about having the right expertise. This leads to a high learning curve for those trying to break into the field. Even seasoned professionals continuously invest time in staying updated, given the rapidly evolving nature of the field. One can see that the journey to building effective models is very time-consuming even for the most experienced professionals.
The American College of Radiology (ACR) sought to establish a cloud-based data lake system to address issues with duplicate records and enhance security controls. ClearScale devised a strategy enabling ACR to securely process, store, expand, and distribute data from Salesforce and its current MSSQL database. Moreover, this simplifies the process of integrating other data sources in the future. Leveraging our expertise in data lake strategies and essential transformations, ClearScale expedited the solution’s delivery.
Amazon SageMaker Low Code/No Code Platforms
First, let’s discuss how AWS offers a great way to help alleviate these obstacles with their Amazon SageMaker Low Code/No Code platforms (LCNC). Amazon SageMaker LCNC offers tools for each step of the ML lifecycle so you can prepare your data, and build, train, and deploy high-quality models faster. These solutions include Amazon SageMaker Data Wrangler, Amazon SageMaker Autopilot, Amazon SageMaker JumpStart, and Amazon SageMaker Canvas. With these, you can increase productivity, deploy ML to production faster, easily prepare data for ML, and quickly experiment with ML models. For this short blog, I’m going to specifically go over Data Wrangler and what it solves.
Amazon SageMaker Data Wrangler is within Amazon SageMaker Studio and it streamlines the machine learning data preparation process. It facilitates easy connections to multiple AWS data sources, allowing users to explore, visualize, and transform their data seamlessly. SageMaker Data Wrangler provides users with capabilities to view data visualizations like histograms and scatter plots, and offers over 300 built-in data transformations!
As users progress with their data preparation, they can visualize the transformation pipeline graphically. Along with this, users can effortlessly export the transformation process into a Python script that replicates the manual steps undertaken, eliminating inconsistencies. The streamlined interface also allows the export of the processing code to different notebooks within the Amazon SageMaker environment, such as SageMaker Processing jobs, Pipelines workflow, or pushing the refined features to Amazon SageMaker Feature Store.
For a quick peak, below is a screenshot of what you’ll see in the “data flow” UI if you begin joining two .csv’s:
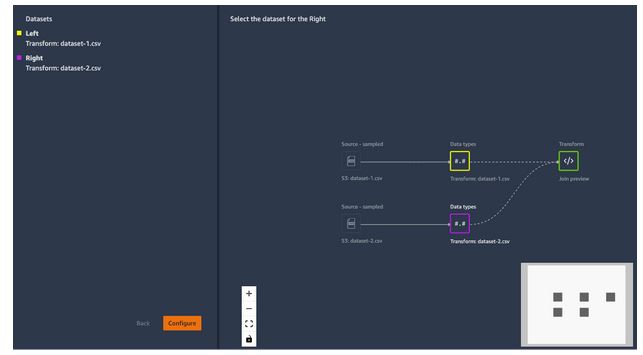
A “data flow” defines a series of ML data prep steps. You can use a flow to combine datasets from different data sources, identify the number and types of transformations you want to apply to datasets and define a data prep workflow that can be integrated into an ML pipeline. It has a very nice UI as you just saw above. Here’s an intuitive list of built-in transformations that auto-populate when you’re looking for one that has an action “drop”:
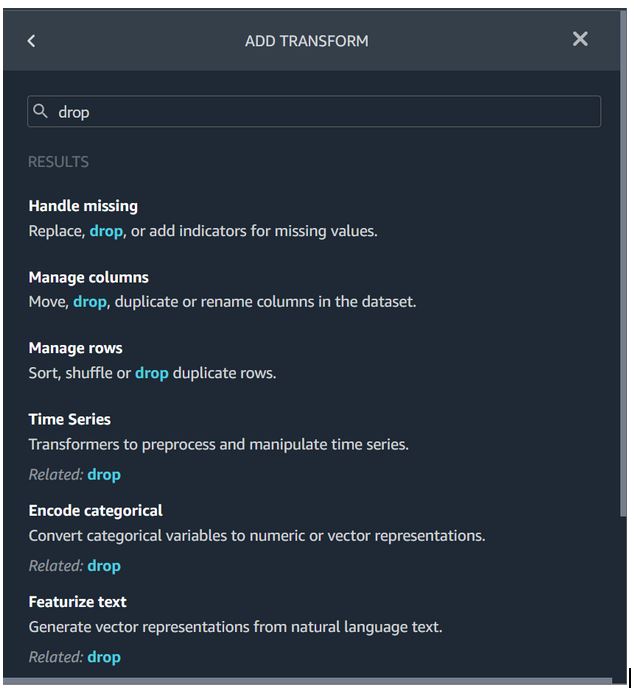
Bringing it back to my original point, the challenge faced by data scientists and ML engineers, and where most of their time is spent on data preparation, is directly addressed by the capabilities of Amazon SageMaker Data Wrangler.
Data Wrangler simplifies the data location process, given its ability to quickly connect to a variety of AWS data sources. Its integrated visualization tools further alleviate the burden on data professionals by offering immediate and comprehensive insights into their data sets. This eliminates the need to rely solely on prior expertise and external tools. The platform’s array of over 300 data transformations aids in efficient data cleaning, reducing the extensive manual work typically associated with this phase. This suite of tools facilitates faster and more accurate data cleaning and transformation iterations.
Finally, SageMaker Data Wrangler allows the enabling the export of the entire data preparation workflow into a consistent Python script. This feature ensures a seamless and error-reduced transition from experimental stages to production environments. In essence, Amazon SageMaker Data Wrangler acts as a comprehensive tool that drastically reduces the time and potential errors associated with data preparation, allowing ML professionals to redirect their focus toward core ML challenges and innovations.
ClearScale Machine Learning Expertise
How does this apply to real use case scenarios, especially at scale? At ClearScale, we leverage SageMaker LCNC tools wherever possible, especially in data lake scenarios. ClearScale is a cloud-native systems integration, strategic consulting, and application development company founded in 2011. The company has successfully delivered more than 1,000 innovative AWS cloud projects for clients ranging from startups to large enterprises.
Specifically, we try to implement SageMaker Data Wrangler in cases where one of our customers’ data ingestion requires data transformations before it’s loaded into a database or warehouse (which you can imagine is very often). Format changes, joins, concatenations, and even custom transformations are that much easier because we can import quickly and visualize what we’re doing in the Data Wrangler console. This ultimately allows us to deliver faster for our customers. What used to take days is not minimized to hours.
ACR wanted to implement a data lake solution in the cloud that would eliminate errors tied to duplicative records, as well as offer more control over security permissions. ClearScale designed a solution where ACR can ingest, store, extend, and publish data from Salesforce and the existing MSSQL database in a secure manner. Furthermore, should the organization want to incorporate additional data sources, it can easily do so. ClearScale was able to deliver this solution quickly due to our knowledge of data lake solutions and the necessary transformations that need to be in place.
Where to Go From Here
The world of machine learning presents a complex challenge with data preparation often being a significant and time-consuming hurdle. Amazon SageMaker, specifically the Data Wrangler component, offers tools that address these challenges head-on, streamlining the data preparation process, and ensuring consistency from experimentation to deployment. Real-world applications, as demonstrated by ClearScale’s involvement with clients like the American College of Radiology, attest to the tangible benefits of implementing data transformations quickly.
As the field continues to evolve, platforms like SageMaker’s Low Code/No Code tools prove to be instrumental in aiding both seasoned professionals and newcomers in navigating the complexities of machine learning. For more information on ClearScale’s machine learning services, visit www.clearscale.com/services/cloud-machine-learning.
Get in touch today to speak with a cloud expert and discuss how we can help:
Call us at 1-800-591-0442
Send us an email at sales@clearscale.com
Fill out a Contact Form
Read our Customer Case Studies

