Data Ingestion Pipeline for Big Data Aggregation and Analysis
Mar 11, 2019

A financial analytics company’s data analysis application had proven highly successful, but that success was also a problem. With a growing number of isolated data centers generating constant data streams, it was increasingly difficult to efficiently gather, store, and analyze all that data. The company knew a cloud-based Big Data analytics infrastructure would help, specifically a data ingestion pipeline that could aggregate data streams from individual data centers into a central cloud-based data storage.
One of the challenges in implementing a data pipeline is determining which design will best meet a company’s specific needs. Data pipeline architecture can be complicated, and there are many ways to develop and deploy them. Each has its advantages and disadvantages.
The company requested ClearScale to develop a proof-of-concept (POC) for an optimal data ingestion pipeline. The solution would be built using Amazon Web Services (AWS). In addition, ClearScale was asked to develop a plan for testing and evaluating the PoC for performance and correctness.
The ClearScale Solution – AWS POC
ClearScale kicked off the project by reviewing its client’s business requirements, the overall design considerations, the project objectives, and AWS best practices.
In addition to the desired functionality, the prototype had to satisfy the needs of various users. That included analysts running ad-hoc queries on raw or aggregated data in the cloud storage; operations engineers monitoring the state of the ingestion pipeline and troubleshooting issues; and operations managers adding or removing upstream data centers to the pipeline configuration.
To make the best use of AWS and meet the client’s specific application needs, it was determined the PoC would be comprised of the following:
- Data center-local clusters to aggregate data from the local data center into one location
- A stream of data from the data center-local clusters into AWS S3
- Amazon S3-based storage for raw and aggregated data
- An Extract, Transform, Load (ETL) pipeline, a continuously running AWS Glue job that consumes data and stores it in cloud storage
- An interactive ad-hoc query system that is responsible for facilitating ad hoc queries on cloud storage
Data Pipeline Diagram
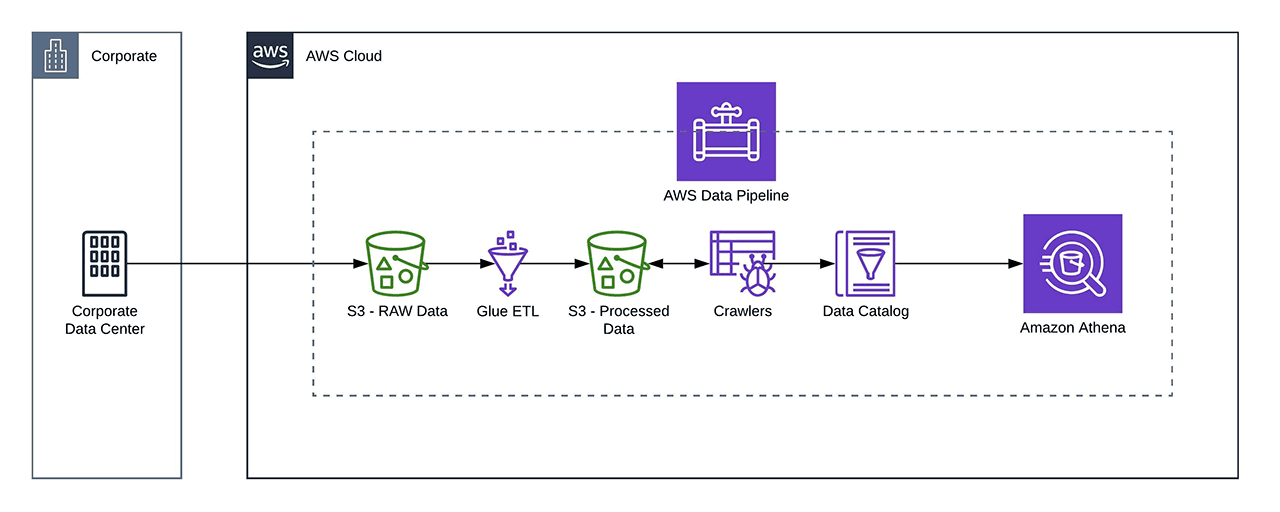
However, the nature of how the analytics application works — gathering data from constant streams from multiple isolated data centers — presented issues that are still to be addressed. Among them:
- Event time vs. processing time — SQL clients must efficiently filter events by event creation time, or the moment when an event has been triggered, instead of event processing time, or the moment of time when the event has been processed by the ETL pipeline.
- Backdated and lagging events — There can be several circumstances where events from one data center lag behind events produced by other data centers.
- Duplicate events — In the event of failures or network outages, the ETL pipeline must be able to de-duplicate the event stream to prevent SQL clients from seeing the duplicate entries in cloud storage.
- Event latency — The target is one-minute latency between an event being read from the on-premise cluster and is available for queries in cloud storage.
- Efficient queries and small files — Cloud storage doesn’t support appending data to existing files. Ensuring one-minute latencies would mean the data in the cloud storage would have to be stored in small files corresponding to one-minute intervals, where the number of files can be extremely large.
ClearScale overcame these issues by outlining the following workflow for the ETL process:
- AWS Glue job writes event data to raw intermediate storage partitioned by processing time, ensuring exactly-once semantics for the delivered events.
- A periodic job fetches unprocessed partitions from the staging area and merges them into the processed area.
- After the data is written, the job updates the Glue Data Catalog to make the new/updated partitions available to the clients.
Architecting a PoC data pipeline is one thing; ensuring it meets its stated goals — and actually works — is another. To ensure both, ClearScale also developed, executed, and documented a testing plan.
The testing methodology employs three parts. The PoC pipeline uses the original architecture but with synthetic consumers instead of ETL consumers. The test driver simulates a remote data center by running a load generator.
With test objectives, metrics, setup, and results evaluation clearly documented, ClearScale was able to conduct the required tests, evaluate the results, and work with the client to determine the next steps.
The Benefits
ClearScale’s PoC for a data ingestion pipeline has helped the client build a powerful business case for moving forward with building out a new data analytics infrastructure. Best practices have been implemented. Potential issues have been identified and corrected. Enhancements can continue to be made.
Once up and running, the data ingestion pipeline will simplify and speed up data aggregation from constant data streams generated by an ever-growing number of data centers. Data will be stored in secure, centralized cloud storage where it can more easily be analyzed. As a result, the client will be able to enhance service delivery and boost customer satisfaction.
From proof of concept to production environments, ClearScale helps companies develop and implement technology solutions to meet their most complex needs. A full range of professional cloud services is available, including architecture design, integration, migration, automation, management, and application development.
Want to learn more about ClearScale’s Data and Analytics Services? Request a consultation today.