Using AWS Batch to Analyze and Extract Information from Large Document Data Stores
Sep 12, 2018

The growth of data stores has grown significantly over the last decade, especially with the introduction of IoT-managed devices, such as medical devices.
From a business perspective, attempting to run reporting and analysis against an ever-growing data store presents issues with some technologies due to the processing time it takes to do transformation routines on increasing volumes of information. When dealing with large volumes of data, finding ways to easily apply transformations and enrichment to data objects can be challenging.
One such client of ClearScale had a similar problem when they requested ClearScale to determine the best approach to this conundrum. They needed a data store that could store large volumes of unstructured and structured data and in turn, be able to search and manage these documents. In order to perform searches, either the documents would have metadata attributes, such as date created or author information, or the contents of the document could be searched.
The Challenge
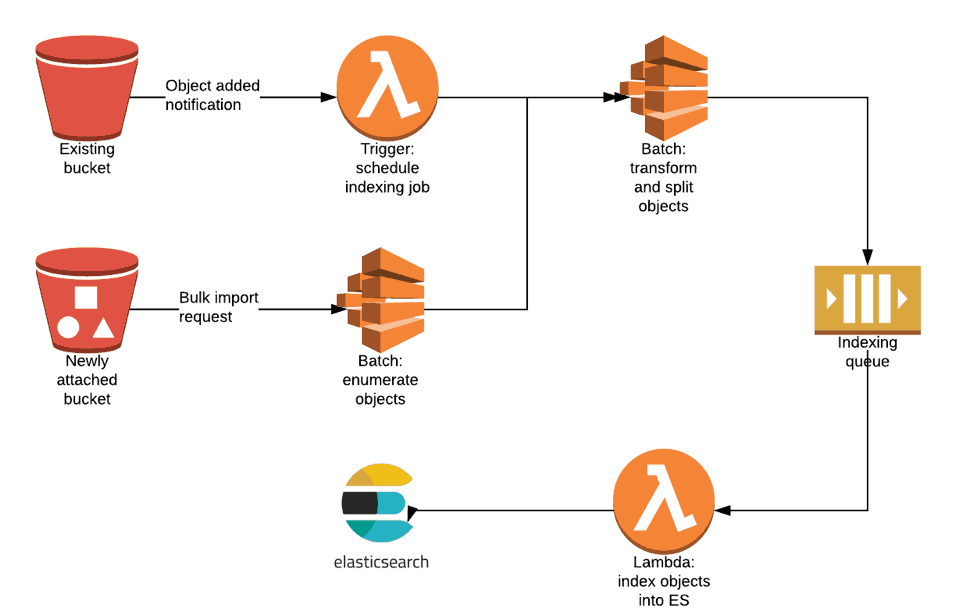
On the surface, the storage portion of the solution was an easy decision. ClearScale determined that by using AWS S3 buckets utilizing AWS ElasticSearch Service for indexing that it would provide the fundamental components of the final solution. Once established, ClearScale could then set up an Extract-Transform-Load (ETL) pipeline that would ingest data from the S3 bucket directly into ElasticSearch for indexing.
However, while in the ETL pipeline the data would need to be augmented, transformed, and enhanced to allow for the ElasticSearch indexing to do its job — this was the challenge that ClearScale faced. Normally, utilizing AWS Lambda could perform these actions, but given the volume of data or documents that needed to be modified in the ETL pipeline, it was apparent that Lambda would not be able to keep pace with the task. ClearScale needed a managed compute engine that would work for longer-running tasks.
The Solution
ClearScale determined one of the optimal ways to solve this issue was to leverage AWS Batch. Using Batch, ClearScale was able to extract text from large documents, often on the order of hundreds of megabytes of data, and then split them into chunks for easier indexing. AWS Batch Processing also allowed ClearScale to enumerate large S3 buckets with hundreds of thousands of documents when doing bulk import operations.
Batch was determined to be the best solution for a variety of reasons beyond these two critical functional aspects. AWS Batch Processing automates scaling based on the volume of incoming tasks to be queued. It also provides extensive monitoring and control features to manage batch processing and ultimately is agnostic of what it’s processing, so long as the job is packaged in a Docker container image.
The Benefit
Ultimately, the solution that ClearScale designed and implemented for the client was viewed as a complete success. It gave the client just what they needed: the ability to support ingestion of large documents and groups of documents by utilizing S3 buckets, and the ability to handle rate limits imposed by AWS ElasticSearch indexing by leveraging AWS Batch for processing and transforming the data.
ClearScale believes that success for any client engagement goes beyond just delivering a solution. The fundamental challenge to any project is the need to understand what the client ultimately needs and ClearScale dedicates substantial resources to understanding every nuance of a client request. The result that is delivered often exceeds the expectations the client has and allows them to leverage the solution for their business operations in ways they never thought possible.