Using Amazon ElasticSearch to Improve Performance when Querying Data in MySQL
Jun 18, 2018

Search tools have increasingly grown in power and functionality over time, and both users and companies have become more reliant on them to identify information and patterns quickly and efficiently. However, even the most robust search tool can experience issues when compiling information from large sets of data. This can be due to either complex relational database joins or the sheer volume of data a single query must parse through to identify the necessary information.
Every industry experiences this at some point in time, and how each company chooses to address these issues depends largely on its philosophy. A recent client of ClearScale’s recognized the need to expand their search abilities but was very much aware of the limitations that their existing MySQL database had. The company asked ClearScale to provide the means to quickly query their data and return results to their users.
The Challenge – Improving Performance While Querying Data
Because our client’s data was so massive, they were experiencing issues being able to effectively return results because of the complex joins their MySQL database had. They needed a way to quickly access and return results using their RESTful API and asked ClearScale to develop a solution.
The solution also needed to offload the queries from the existing MySQL database to reduce the impact on performance. It needed to have a scalable architecture so that as the size of the data and the reliance on the search queries grew, the overall solution would not be adversely impacted.
The Solution – Amazon ElasticSearch
In order to achieve success, ClearScale recognized that moving the data into Amazon ElasticSearch was the best solution. This would allow for a more scalable solution long-term, but since the API queries needed to then use ElasticSearch for the results, there was no simple out-of-the-box solution readily available. If an out-of-the-box solution were used, it would mean denormalizing documents stored in the ElasticSearch data store and updating them whenever the MySQL tables were updated.
Live Sync from MySQL to Amazon ElasticSearch Diagram
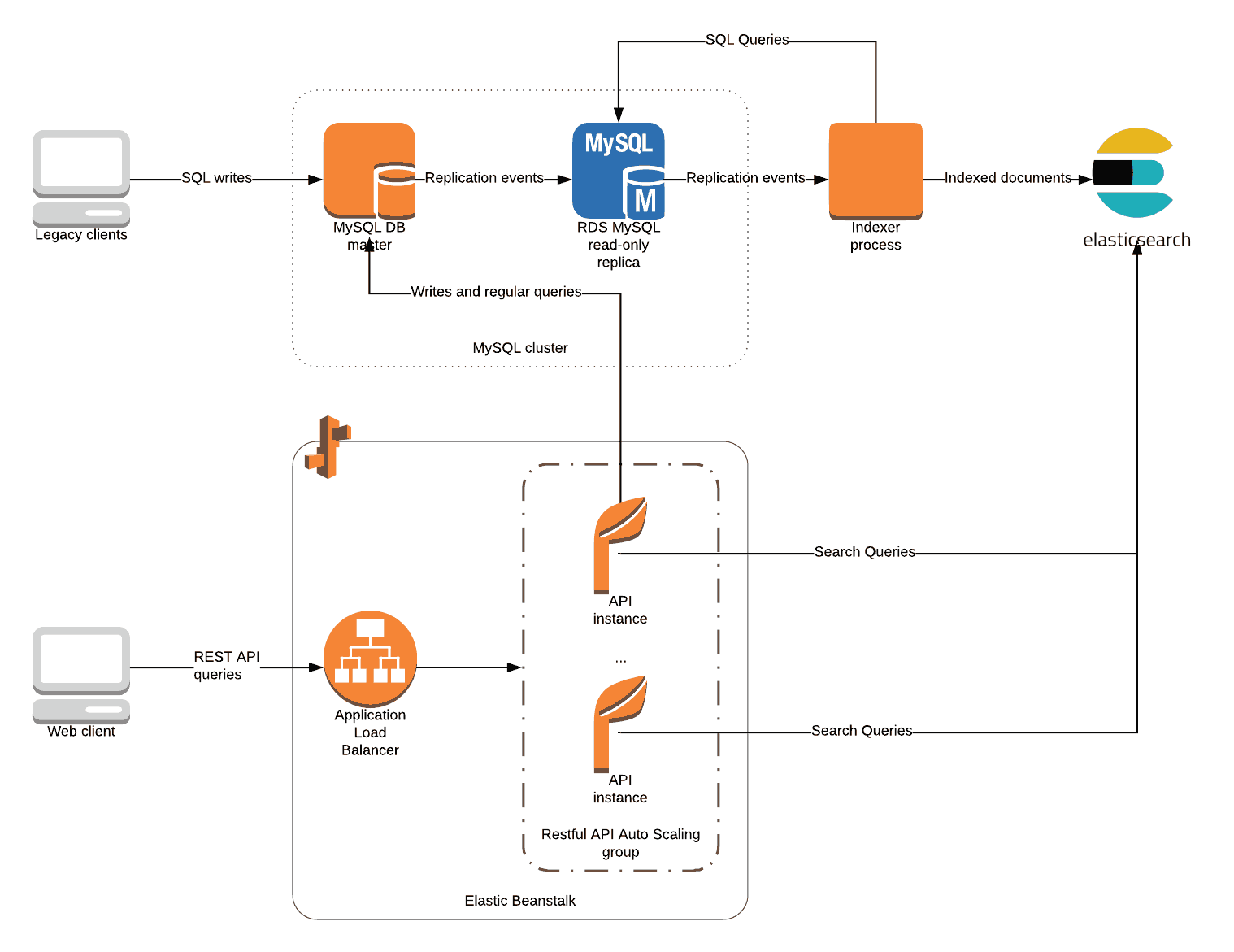
Although ClearScale was able to set up a dedicated indexing pipeline from the MySQL instances into ElasticSearch for the initial upload of the data, trying to keep it in sync with the MySQL tables was the larger challenge. To do so, there were two possible approaches that could be taken, neither of which would really be feasible for long-term use.
Option 1 would be a SQL-based approach, where a query is run and uploaded to ElasticSearch on a semi-frequent basis. This one is difficult to implement with incremental indexing. Or, option 2 would be using a replication log-based approach where the indexer listens for replication events that the MySQL database generates and then indexes. The latter approach could be partially successful, but the only data that could be uploaded would be from individual rows, and it would not allow table joins; this means loss of rich data and ultimately is counter to the long-term vision of what the client was looking for.
A Hybrid Approach
ClearScale decided on implementing a hybrid approach that adopted the best of both models. ElasticSearch documents were created from data obtained from MySQL queries, but the queries themselves were triggered based on events generated from the replication logs. The data was then sent over the dedicated indexing pipeline and an AWS ElasticSearch cluster was created to house the data.
ClearScale then modified the existing RESTful API to perform search queries against the ElasticSearch instance. Working closely with the client, ClearScale determined what search criteria would be available to consumers of the API. The resulting search service would group the search criteria into an equivalent ElasticSearch query and return the results directly to the client, thus bypassing the MySQL database and maintaining a high throughput of queries to results.
The Benefits
The approach that ClearScale adopted had immediate success. Because of the ElasticSearch cluster coupled with a MySQL RDS Replica used during the initial data import, the solution allowed for indexing rates of around 100 documents per second, keeping performance relatively high. In addition, offloading the queries from the MySQL database onto the ElasticSearch solution improved the overall performance of the MySQL database, which in turn allowed updates from the database to the ElasticSearch cluster to propagate in just a few seconds. Finally, having the search service directly interact with ElasticSearch to produce results from queries from clients meant a higher response rate overall within a scalable instance.
ClearScale has been devising creative Big Data solutions for complex client requirements since 2011. With the wealth of information our engineers, architects, and solution designers have obtained through many client interactions, ClearScale can find favorable outcomes that are scalable and dynamic enough to meet your current and future needs.