Amazon DataZone and the Rise of Data Mesh
Aug 29, 2023

By Anthony Loss, Director of Solution Strategy, ClearScale
Data Mesh is a concept rooted in decentralizing responsibility for data to those closest to it, enabling scalability and continuous evolution. It uses business domains for decomposition, limiting the impact of constant change to these domains, thereby creating ideal units for distributing data ownership.
The Building Blocks of Data Mesh: Roles and Requirements
Legacy data architectures often struggle with the cost and friction of discovering, understanding, and utilizing high-quality data. Data Mesh, a principle focused on decentralization, aims to solve this by treating data as a product, with data providers viewing data consumers as customers. The framework requires certain capabilities such as data discoverability, security, and trustworthiness, necessitating new roles like domain data product owners who ensure data is delivered as a product, and understand users’ needs and preferences. These owners are supported by data product developers, who build, maintain, and serve data products, potentially forming new teams for data products that don’t align with an existing domain.
Data Mesh, in its architectural design, introduces the concept of a data product as its smallest independently deployable unit. This data product, acting as a node on the mesh, contains three essential structural components: code, data and metadata, and infrastructure.
The code comprises pipelines for data consumption, transformation, and serving, APIs for data access, and enforcement of traits like access control. Data and metadata encapsulate analytical and historical data in various formats with associated metadata, while the infrastructure provides the platform for running the data product’s code, along with storage and access to the large data and metadata.
Data Infrastructure as a Platform
Building, deploying, and managing a data product requires specialized infrastructure skills, making it challenging for each domain to replicate this process independently. To enable domain autonomy, the principle of self-serve data infrastructure as a platform is introduced, providing high-level abstractions to simplify provisioning and management.
Despite the technology stack for data products being different from that of services, the hope is for a convergence where operational and data infrastructure coexist seamlessly. The self-serve platform must offer a new category of tools and interfaces to generalist developers, lowering the cost and the specialized knowledge currently needed to build data products, and providing capabilities like scalable data storage, data pipeline orchestration, and data locality.
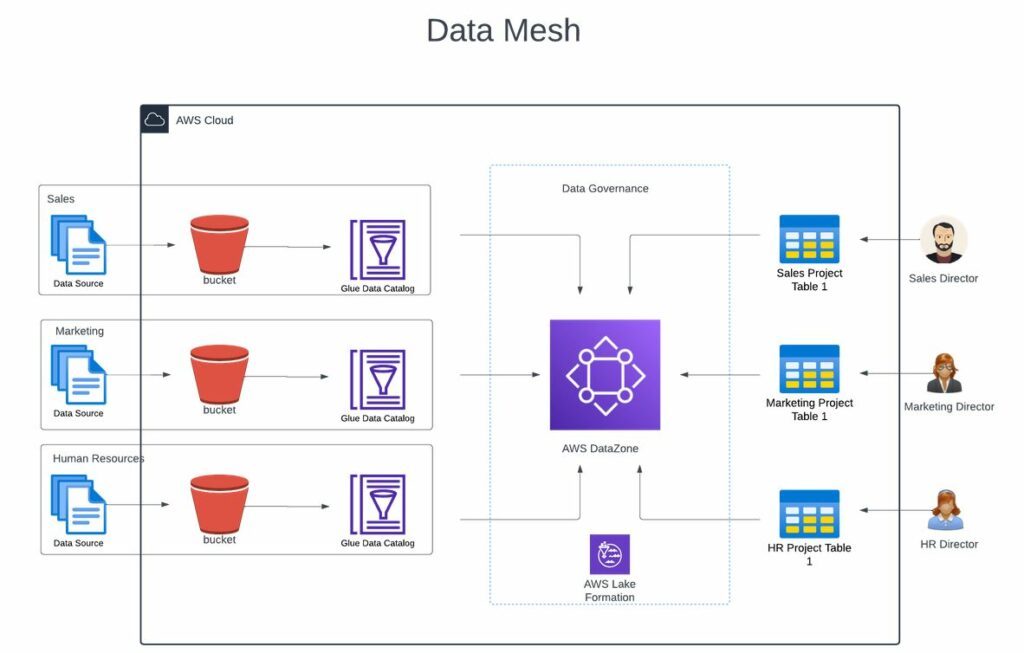
Amazon DataZone: A Real-World Application of Data Mesh Architecture
Amazon Web Services (AWS) offers Amazon DataZone to deliver this data mesh architecture in a managed, self-service platform enabling true governance. DataZone allows its customers to discover and share data at scale across organizational boundaries with governance and access controls. It has been a major problem for AWS customers to have fine-grained access controls to govern data. AWS has LakeFormation to enable fine-grained access control, but this management of IAM roles and policies can be cumbersome. Amazon DataZone solves this.
“DataZone enables you to set data free throughout the organization safely by making it easy for admins and data stewards to manage and govern access to data,” said Adam Selipsky, CEO of AWS. “And it makes it easy for data engineers, data scientists, product managers, analysts, and other business users to discover, use, and collaborate around that data to drive insights for your businesses.”
DataZone utilizes AWS Glue and Glue Data Catalogs to segment data and serve as a product.
Understanding the Multifaceted Planes of Data Mesh
You can divide Data Meshes into different planes, each serving a distinct profile of users. These planes, each representing an integrated but separate level of existence, include the Data Infrastructure Provisioning Plane, which supports the underlying infrastructure needed to run data product components. Another plane is the Data Product Developer Experience Plane, which offers a simpler interface to manage a data product’s lifecycle, automatically implementing standards and global conventions. Finally, the Data Mesh Supervision Plane provides capabilities at the mesh level, such as data product discovery and the ability to correlate data products for higher-order insights.
Data Mesh follows a distributed system architecture consisting of independent data products that need to interoperate for maximum value extraction. This necessitates a governance model that supports decentralization, domain self-sovereignty, interoperability through standardization, dynamic topology, and automated decision-making by the platform, termed federated computational governance.
This model grants autonomy to domain data product owners and data platform product owners while setting global rules to ensure a healthy, interoperable ecosystem. Unlike traditional governance of analytical data management systems which centralize decision-making and minimize support for change, Data Mesh’s federated computational governance embraces change and multiple interpretive contexts.
Balancing global standardization and domain autonomy is key in a federated governance model. Traditional governance practices, like certification of golden datasets by centralized functions, are no longer applicable in the Data Mesh paradigm. Instead, a domain dataset becomes a data product after local quality assurance processes, under global standardization rules set by the federated governance team and automated by the platform.
Final Thoughts: The Transformative Impact of Data Mesh
In conclusion, Data Mesh is a revolutionary approach to data architecture and governance that aims to solve the scalability and evolution challenges of traditional centralized models. It does this by decentralizing responsibility for data, viewing data as a product, and enabling domain autonomy. The introduction of key roles like domain data product owners and data product developers ensures that data meets user needs and preferences.
The Data Mesh model’s architecture emphasizes self-serve data infrastructure as a platform, with data products consisting of code, data and metadata, and infrastructure. This model enables an easier interface for managing a data product’s lifecycle and provisions for scalable storage, pipeline orchestration, and data locality. Furthermore, Data Mesh adopts a federated computational governance model, which combines the advantages of domain autonomy and global standardization, fostering a healthy and interoperable data ecosystem.
Finally, Amazon DataZone, while still in preview at the time of this writing, will enable organizations of all sizes to quickly and securely implement Data Meshes in their environments. As such, the Data Mesh paradigm, while still nascent and evolving, holds immense promise for businesses grappling with the complexities and limitations of centralized data architectures.
Ready to revolutionize your organization’s data architecture and governance with Data Mesh? ClearScale can help you transition from a legacy centralized model to a scalable, self-serve Data Mesh paradigm. Contact our cloud experts today to set your organization on the path to greater scalability, security, and business agility.
Call us at 1-800-591-0442
Send us an email at sales@clearscale.com
Fill out a Contact Form
Read our Customer Case Studies
